In addition to extending my first piece on this site into a paper, I also had the pleasure to participate in Neel Nanda's MATS 9.0 training phase since I wrote that first piece (now the blogs are really flowing!). I can't say enough how great an experience this was, but in this post I'd like to write a little bit about my first mini-project during the program: Automated Jailbreak Detection for LLMs.
I'm especially excited about this since my sprint project (blog post to come) on deception detection, combined with this work, has made me very bullish on the potential for automated probe creation. While this post in and of itself might be less novel or shocking, I feel it concretely provides the intuition and motivation for automated probe creation.
Mini-Project Details
I had the pleasue of working with David Vella Zarb (one of many amazing people I meet during the training phase) on this project. Together, we iterated upon Anthropic's Rapid Response paper. In short, this paper focuses on dynamic jailbreak prevention by leveraging agents to generate a dataset of an example exploit to then test how several defense mechanisms can prevent the specified behavior. The best method in the paper was Guard Fine-tuning, which fine-tunes an LM-based input classifier using known example jailbreaks, attack proliferations, and benign prompts.
One mechansim the paper did not explore was probing. This was our mini-extension of Rapid Response, we adapted the LLM proliferation agent for Gemini Flash (there were difficulties getting non-google models to participate as red team assistants) and created probes based on 100+ contrastive pairs of a user-specified jailbreak behavior.
Concretely, we have an attack-LLM that tries to create the user-specified jailbreak behavior. Once it succeeds, this agent then proliferates the jailbreak across different prompt scenarios. After hitting a sufficient dataset size, probes are trained on these jailbreak prompts (our harmful set) and the same amount of non-toxic prompts from WildChat (our non-harmful set). So, very similar to Guard Fine-tuning, but instead of a classifer we use mass-mean probes for jailbreak prevention.
Despite the simplicity of this apporach, it was pretty effective - results from an example where the specified jailbreak is "roleplay to make bio-weapons":
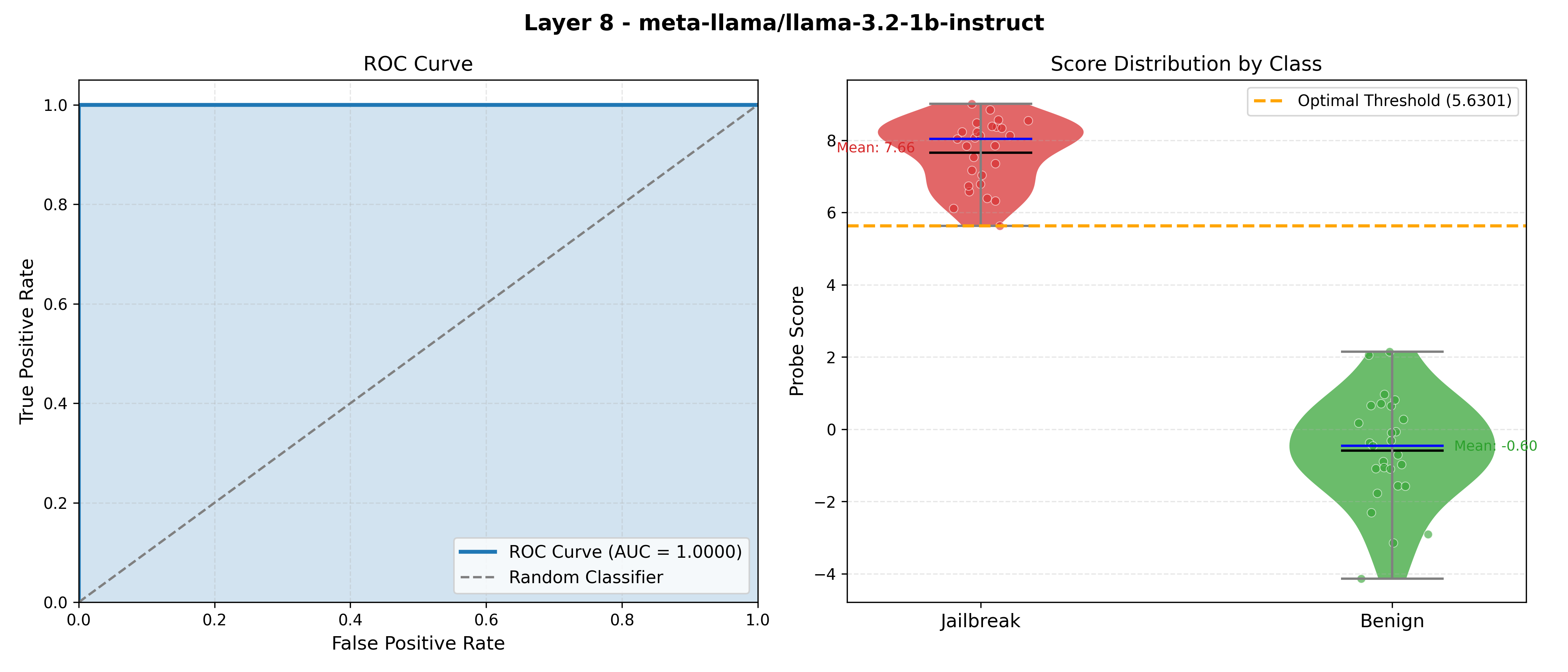
Note, results will vary depending on the complexity of the jailbreak behavior you are testing for, but in limited
testing the roc score typically was above 0.85. For those curious, the code can be found
here.
Though this codebase is still in a bit of a mess, those who are motivated should be able to get it to run with
python3 main.py (see the appendix for pip install instructions).
What it Motivates
Naturally, while thinking of a topic for a sprint project, I spent some time trying to determine how this might generalize. The most obvious project seems to be automated probe creation. Though it's a bit vague how the quality of these probes can be evaluated. Yes, LLMs offer cheap and fast cognitive power (relative to humans building the dataset for probing), so, naively, in a shot-gun approach an LLM agent should be more than capable of creating a dataset for a quality probe. Though, this might be easier for certain tasks (like jailbreaks) than others, especially for those tasks where you can be convinced that the probe is working from just inputs and outputs.
So, how do we verify the work of these LLM agents in more complex situations? Say we wanted to probe for deception to prevent the model from pursuing its own agenda while we remain oblivious to the fact - how would this work?
Well this is where I'd be getting ahead of myself, as we need another couple of write-ups to arrive to the following conclusion. However, to avoid any potential suspsense, I believe the answers is SAEs (sometimes it feels like SAEs are always the answer in MI, even with all the push-back they've gotten recently).
This belief is a bit more baked than just speculation. In brief, for the deception detection sprint project, it became clear that probing for a specific semantic concept is diffcult to do in a black-box fashion. This was done by taking the cosine similarity of probes with SAE decoder directions, which tells us what concepts the probe is predominantly measuring. Between this evaluation step and thinking about "wouldn't it be nice if we could tell our data was good before trusting it for probe creation and deployment", we arrived at the following conclusion: building probes in a black-box fashion is hard. Therefore, it seems worth to explore SAEs as a reference point during dataset construction for probes. It seems reasonable to say that an LLM agent with this information should perform at least on par with an LLM agent that only has black-box information, though I'd argue it should perform better.
In future posts detailing the deception detection sprint project and automated probe creation, I'll dive much more into this.
Appendix
In reference to the "difficulties" faced above getting over models to comply for red teaming, it was really only Gemini that was willing to play attack-LLM across the frontier models.
Perhaps uncoincidentally, it was the easiest to get an attack-LLM to work on as well:
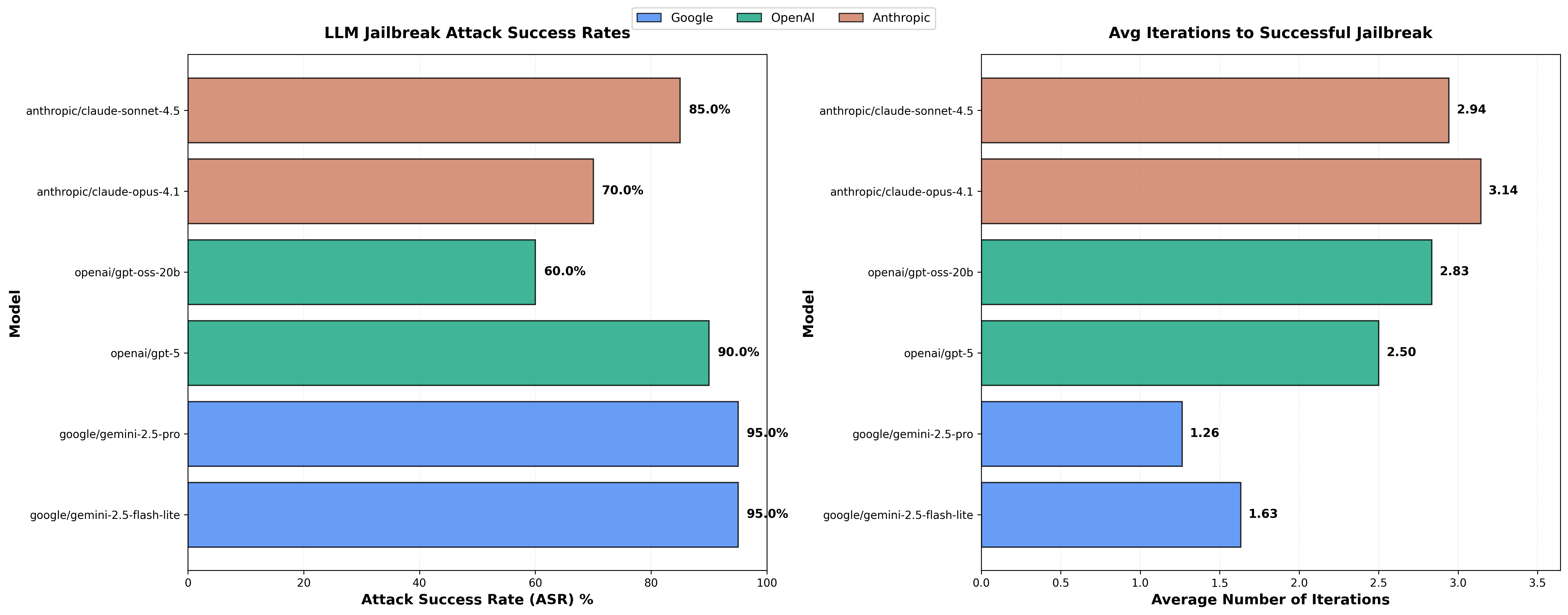
Granted, this is a very small sample size (20 attacks per model - each with up to 5 retries). Additionally, it might be a little weird that our attack-LLM is Gemini itself (though again, none of the other models above were really willing to cooperate as the attack-LLM).
It is a small sample size, but interesting to see how much more cooperative the Google models are for red teaming.
Pip install command to get the code up and running:
pip install torch transformers fire numpy pandas scikit-learn requests python-dotenv tqdm
Note: You'll also need to add a .env file with an OPENROUTER_API_KEY.